6G Future Lab Bavaria
6G Future Lab Bavaria is one of the first 6G-oriented research projects in Europe. It is funded by the Bavarian Ministry of Economic Affairs, Regional Development and Energy and it aims to explore approaches that tackle emerging problems in future generations of mobile communications. More information can be found in the project website: 6G Future Lab Bavaria
We at LIS are involved in the subproject TP7 together with our colleagues at LDV. Our goal is to develop fast, agile, ML-enhanced network node extensions.

Research Focus
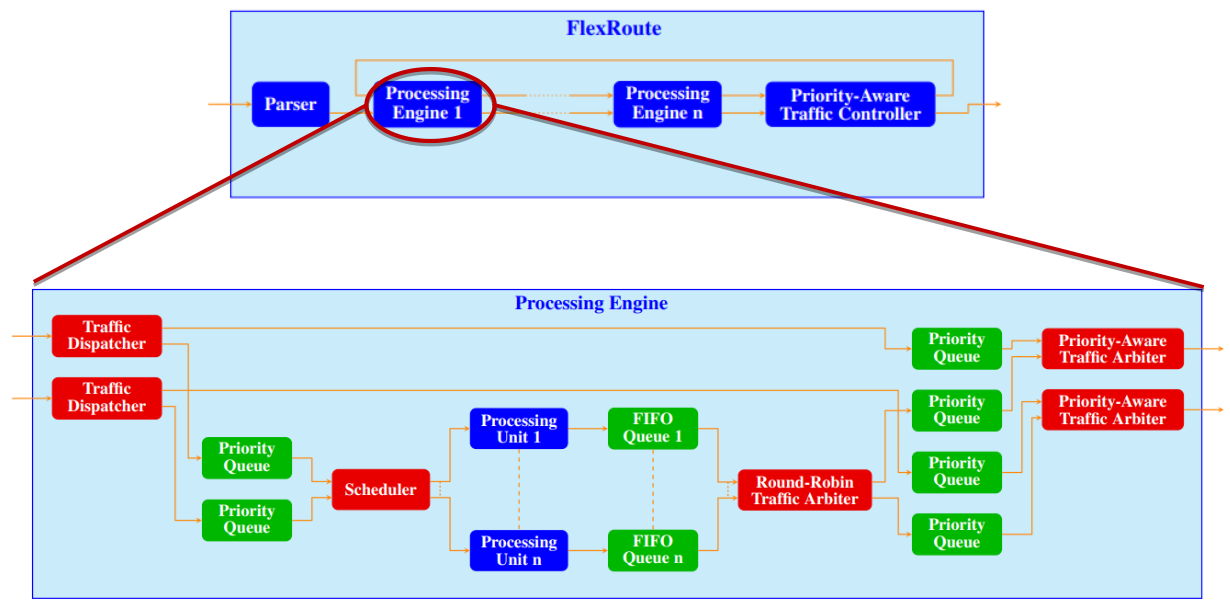
Our latest proposal is FlexRoute, an efficient packet-processing design characterized by high speed, adaptability and priority awareness, enabling the processing of packets with varying sizes and processing requirements at a traffic rate exceeding 100 Gbit/s on FPGA platforms. FlexRoute employs a pipeline of processing engines, arranged based on the most probable traversal order. Each processing engine comprises parallel processing units, a priority-aware scheduler, and flexible forwarding logic. This design facilitates the option for incoming traffic to bypass unnecessary processing units based on the specified processing requirements of the associated flows. The scheduler prevents head-of-line blocking for high-priority packets by refraining from dequeuing any packet when the actual throughput surpasses the bandwidth of the processing engine. Furthermore, the execution sequence can be dynamically reconfigured for each flow, and packets may be rerouted through an additional pipeline channel if they necessitate a different order of processing engines. Fig. 1 depicts the architecture of FlexRoute.
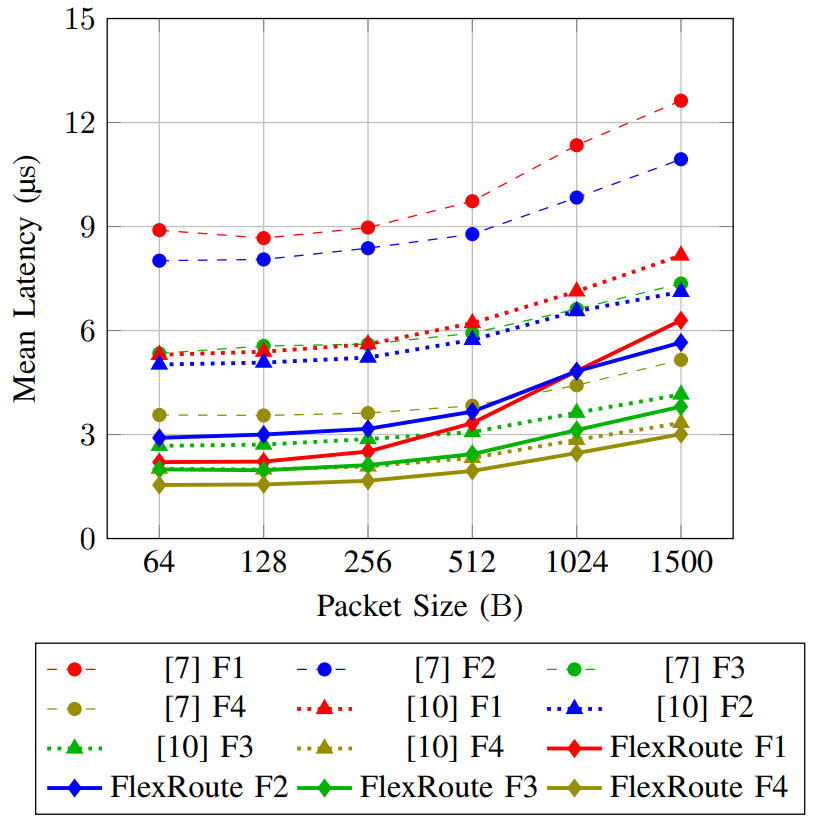
We implemented a prototype of FlexRoute in Verilog and compared it with two state-of-the-art packet-processing designs in terms of throughput and latency. The measurements are obtained from cycle-accurate RTL simulations in Vivado. Fig. 2 shows the mean latency for packets of different size associated with four flow types with different processing requirements that is measured in PANIC, FlexPipe and FlexRoute when receiving traffic at a rate of about 70 Gbit/s. FlexRoute achieves a lower mean latency than PANIC and FlexPipe on a per-flow basis for packets of any size. Flow 1 experiences the most significant latency improvements because it has the highest priority.
6G Testbed - NETTB
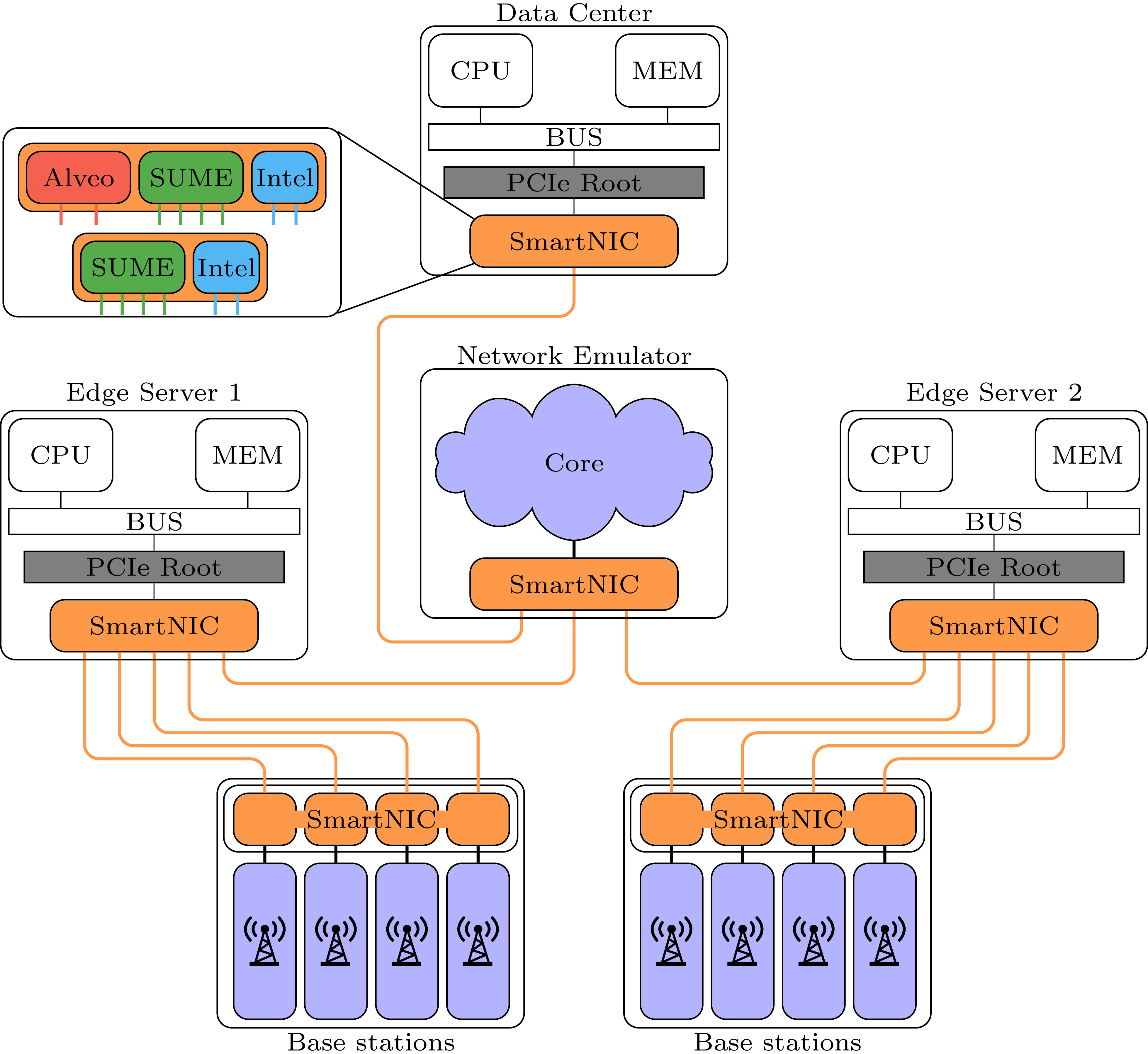
The LIS 6G NETworking TestBed and Demonstrator (NETTB) consists of several server nodes (AMD Epyc, Ryzen and Intel Xeon), which are equipped with several Xilinx FPGAs (NetFPGA SUME and Alveo U55C), as well as commercial Intel NICs, further accompanied by Xilinx Zynq MPSoCs. They are used for prototyping 6G-specific SmartNIC extensions, providing proof-of-concept evaluation and demonstration in a physical networking testbed. The nodes can be used in a variety of ways, depending on the specific use case and evaluation setup. The figure on the right shows an exemplary representation of the nodes in a typical 6G use case.
A demonstration of the research goals of subproject TP7 is available here: https://nextcloud.cit.tum.de/index.php/s/dAkcGenpaYpAoiC. The demo shows a 6G scenario of a moving user, who is using an object detection service in the network. To mitigate processing overloads and high latencies incurred by the user mobility and load fluctuations, an AI-assisted, load-aware service migration mechanism is developed.

Student Projects
Available Projects
Ongoing Projects
Finished Projects
Betreuer:
Student
Betreuer:
Student
Betreuer:
Student
Betreuer:
Student
Betreuer:
Student
Publications
- HiPerNoC: A High-Performance Network-on-Chip for Flexible and Scalable FPGA-Based SmartNICs. 2025 Design, Automation & Test in Europe Conference (DATE), 2025 mehr… BibTeX Volltext ( DOI )
- FlexCross: High-Speed and Flexible Packet Processing via a Crosspoint-Queued Crossbar. 2024 27th Euromicro Conference on Digital System Design (DSD), 2024 mehr… BibTeX Volltext ( DOI )
- FlexRoute: A Fast, Flexible and Priority-Aware Packet-Processing Design. 2024 32nd Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), 2024 mehr… BibTeX Volltext ( DOI )
- ecoNIC: Saving Energy through SmartNIC-based Load Balancing of Mixed-Critical Ethernet Traffic. 27th Euromicro Conference on Digital System Design (DSD) 2024, 2024 mehr… BibTeX Volltext ( DOI )
- FlexPipe: Fast, Flexible and Scalable Packet Processing for High-Performance SmartNICs. 2023 IFIP/IEEE 31st Conference on Very Large Scale Integration (VLSI-SoC), 2023 mehr… BibTeX Volltext ( DOI )