- 2/2A Folded Pipeline Network Processor Architecture for 100 Gbit/s Networks. ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), 2010 more… BibTeX
- 1/2Packet Processing at 100Gbps and Beyond - Challenges and Perspectives. 10. ITG-Fachtagung Photonische Netze, 2009 more… BibTeX
NPU100 - Design of a Network Processor Datapath for 100Gbit/s Carrier Grade Ethernet
Motivation and Targets
With the standardization process for 100Gb/s Ethernet being already well underway, related work on equipment for all required layers is starting to take shape. This ranges from physical layer work on optic fibers and the appropriate optical components to protocol development for efficient packet transport. The 100 Gigabit Ethernet (100GET) project aims to bring affordable, widely available Ethernet technology to the core network. So far Ethernet has dominated local networks but its use in the core has been inhibited due to lack of desired carrier grade features (management, QoS, etc). To accomplish this, 100GET will investigate a variety of issues from the lowest physical layer to high layer cost efficiency studies.
The goal of the NPU100 project is to investigate various architectural alternatives which will allow for efficient and flexible 100 Gbit/s processing. The resulting design should achieve its target throughput, while allowing for reduced power consumption. To prove the performance of the defined architecture, it will then be implemented in an FPGA demonstrator, which is expected to run at lower speed (e.g. 10 Gbps), which will enable a detailed analysis of the performance of a possible implementation.
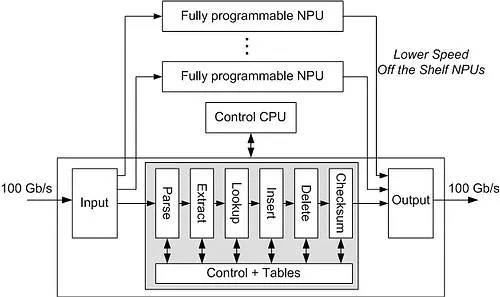
Approach and Results
Our contribution to 100GET, called NPU100 involves designing the core of a network processor which will be able to process packets at 100 Gb/s. This differs significantly for typical NP architectures since most of the forwarding in the 100 Gb/s core network will be done by using mainly Lavel 2 function by employing appropriate protocols like T-MPLS and PBB-TE.
This allows us to divide the approach into a fast weakly programmable pipelined architecture which swiftly forwards packets and parallely operating fully programmable NPs which handle packets that require additional processing. The weakly programmable pipeline will be made up of several stage which will be a decomposition of the functionality specified by the supported protocols. The resulting design should be a tradeoff between performance, circuit complexity and power consumption.
Initially three architectures were defined within the project, which were then qualitatively and quantitatively analyzed to determine which is the most suitable for the project goals. This investigation led to the selection of a folded pipeline architecture, where a long pipeline is broken into pieces, which are then parallelized. Headers which require additional processing pass through more than one pipeline fragments until their processing is complete.
After selecting an architecture, the required processing modules were specified and implemented in VHDL, along with any additional modules required for the operation of the folded pipeline concept. The design was then downloaded to a Virtex 5 FPGA and its performance and functionality was verified.