IPF2: Towards Networked and Data-Centric Platforms
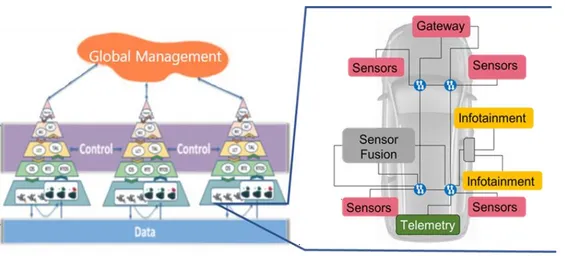
The IPF2 project focusses on expanding the factory concept of IPF1 towards multiple, networked and heterogeneous multicore processors. A very well known application would be a distributed ECU(electronic control unit) infrastructure found in modern automotive vehicles (see picture above). In such a distributed ECU, multiple multicore processors with different levels of heterogeniuity (e.g. CPUs, GPUs, FPGAs) are connected together using a high speed communication networks e.g. time sensitive networks (TSNs). In such automotive vehicle architectures, a large amount of data is being generated on the vehicle by the high quality, high data rate sensors (e.g. cameras, lidar, radar) and also the data generated by vehicular functions such as advanced driver assistance (ADAS) and highly autonomous driving (HAD) functions. To address the processing and transfer of such a large amount of data, we forsee the necessity to shift from a predominantly compute-centric in architecture development towards a holistic compute- and data-centric perspective. The IPF2 project with its new data-centric perspective will affect where and how data is stored, transferred and processed within a vehicle, as well as between different vehicles in the future (e.g. vehicle platooning).
Our work

Towards the goal of a data-centric perspective design of networked multi-core processors, our work at TUM addresses two major problems:
1. Developing configurable dynamic NUMA for faster memory access among network connected multi-core systems.
Modern vehicle architecture are made up of a few domain specific computers plus one or more high performance units for automated driving and sensor fusion. The compute units are connected together by a Time Sensitive Network (TSN) which is a real-time version of Ethernet. The sensors generate a lot of data which are fused by the sensor fusion entity and stored in a centralized location. The results can then be accessed over the network. This compute-centric approach although cost-efficient is not power and performance optimal. Factors such as access latency, network load and power consumption strongly depend on the distance between the data i.e memory and the processing units. Dynamic-NUMA focusses on allowing the network-connected architectures to directly access the memory of the other networked nodes in a decentralized manner to improve performance.
2. Task and Data Migration Mechanisms using Learning Classifier Tables
In modern vehicles, data is generated from different locations and are processed. The execution time of the task processing the data is highly dependent on where the data is generated and stored. The performance of the task can be improved by either moving the data closer to the task or vice versa. In this work, we track different metrics such as number of memory accesses to local node and networked node, execution time, power consumption of the processing node and use them in conjunction with our Learning Classifier Tables, to learn a policy in runtime to either migrate the task or the data in the networked architecture.
Interested? Apply to open positions below or contact us by email.
If you are interested in our IPF project and want to get involved in projects that involves around data-centric architecture development, dynamic NUMA, task and data migration in network connected heterogenous multi-core systems, please feel free to apply to one of the positions available below or contact the respective staff members.
Thesis Offers
Ongoing Thesis
Publications
2024
- EPIC-Q : Equivalent-Policy Invariant Comparison enhanced transfer Q-learning for run-time SoC performance-power optimization. International Conference on Embedded Computer Systems: Architectures, Modeling and Simulation 2024, 2024 more… BibTeX
- XCS with dynamic sized experience replay for memory constrained applications. Genetic and Evolutionary Computing Conference (GECCO), 2024 more… BibTeX Full text ( DOI )
2023
- LCT-TL: Learning Classifier Table (LCT) with Transfer Learning for run-time SoC performance-power optimization. 16th IEEE International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC 2023), 2023 more… BibTeX
- LCT-DER: Learning Classifier Table with Dynamic-sized Experience Replay for run-time SoC performance-power optimization. The Genetic and Evolutionary Computation Conference (GECCO), 2023 more… BibTeX Full text ( DOI )
- CoLeCTs: Cooperative Learning Classifier Tables for Resource Management in MPSoCs. 36th International Conference on Architecture of Computing Systems, ARCS 2023, 2023 more… BibTeX Full text ( DOI )
- Machine Learning in Run-Time Control of Multicore Processor Systems. it - Information Technology 0 (0), 2023 more… BibTeX Full text ( DOI )
- Information Processing Factory 2.0 - Self-awareness for Autonomous Collaborative Systems. DATE 2023, 2023 more… BibTeX Full text ( DOI )
2022
- GAE-LCT: A Run-Time GA-Based Classifier Evolution Method for Hardware LCT Controlled SoC Performance-Power Optimization. Architecture of Computing Systems, 2022 more… BibTeX Full text ( DOI )
2021
- SEAMS: Self-Optimizing Runtime Manager for Approximate Memory Hierarchies. ACM Transactions on Embedded Computing Systems (TECS), 2021 more… BibTeX Full text ( DOI )
2020
- The Self-Aware Information Processing Factory Paradigm for Mixed-Critical Multiprocessing. IEEE Transactions on Emerging Topics in Computing, 2020, 1-1 more… BibTeX Full text ( DOI )
- Emergent Control of MPSoC Operation by a Hierarchical Supervisor / Reinforcement Learning Approach. DATE 2020, 2020 more… BibTeX Full text ( DOI )
2019
- SOSA: Self-Optimizing Learning with Self-Adaptive Control for Hierarchical System-on-Chip Management. Proceedings of the 52Nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO '52), ACM, 2019 more… BibTeX Full text ( DOI )
- The Information Processing Factory: A Paradigm for Life Cycle Management of Dependable Systems. ESweek, 2019 more… BibTeX Full text ( DOI )