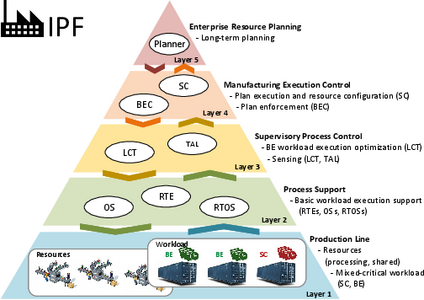
Autonomous Systems Design must deal with several impairments that arise in designing and deploying complex autonomous systems. Chief among such impairments are:(1) the unexplainability conundrum of AI/ML leading to unbounded behavior, (2) the intractability of verifying the system under all possible use cases, leading to the inability to deal with unexpected situations (e.g., emergent behavior and unknown unknowns, or black swan events), (3) the inability to fully predict the behavior of humans entangled with such systems (e.g., self-driving cars interacting with human-driven ones), (4) the aging and other physical world interaction mechanisms that ultimately affect the system’s operational parameters (e.g., energy, performance, reliability, safely and security) over time, (5) the inaccuracy of the models used at different levels of hierarchy to design the system, and (6) the need to reconcile conflicting operational parameters. The Information processing Factory (IPF) project is a collaboration between research teams in the US (UC Irvine) and Germany (TU Munich and TU Braunschweig) applying self-awareness to the self-management of MPSoCs. This includes (a) self-reflection, i.e., awareness of the MPSoC’s own hardware/software architecture, operational goals, and dynamic changes once deployed; (b) self-prediction of dynamic changes; and (c) self-adaptation to environment changes, optimizing operational parameters and protecting against unexpected situations with increased risk. The IPF paradigm applies principles inspired by factory management to the continuous operation and optimization of highly integrated embedded systems as shown in the corresponding figure. A general objective is to identify a sweet spot between maximized autonomy among IPF constituent components and a minimum of centralized control to ensure guaranteed service even under strict safety and availability requirements. Emphasis is on self-diagnosis for early detection of degradation and imminent failures combined with unsupervised self-adaptation to meet performance and safety targets in a mixed-critical environment.
Our Work
Learning Classifier Table
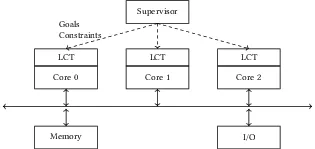
A mixed critical system consists of safety critical tasks and best effort tasks co-existing in the system. The safety critical tasks have strict requirements w.r.t. response time, execution deadline and resource requirements wheas the best effort tasks are required be executed without affecting the safety critical tasks by adhering to constraints. to Our work at TUM focusses on the optimizing the workload execution of best effort tasks in the mixed critical domain. In the IPF project, we developed Learning Classifier Tables (LCTs) which are light-weight, classifier based, human intepretable, hardware implemented and machine learning build blocks inheriting the concepts of learning classifier systems. LCTs are used as low-level controllers for the processing cores (executing best effort tasks) in the system-on-chip executing mixed critical tasks. LCTs learn to adapt and to optimize the operating point of the core in run-time to provide the performance targets required by the best effort tasks (IPS, FPS, response time) while adhering to system constraints (e.g. power budget, temperature). The performance targets and system constraints are dynamically changed in run-time by the best effert controller (BEC) and are reflected in the learning process of the LCT via objective and reward functions. Our main research and work focusses on the following topics related to LCTs:
1. Design of objective and reward function to reflect the performance targets and system constraints
2. Enabling coordination among the LCTs to improve performance. Different LCTs are used to control the different cores in an multi-core SoC. The LCTs learn to achieve their given goals within specified constraints. However, in certain situations it is beneficial to have a common unified goal and constraint for multiple LCTs. In such situations, the LCTs must learn to obtain their common goal via coordination. More details available in the following article.
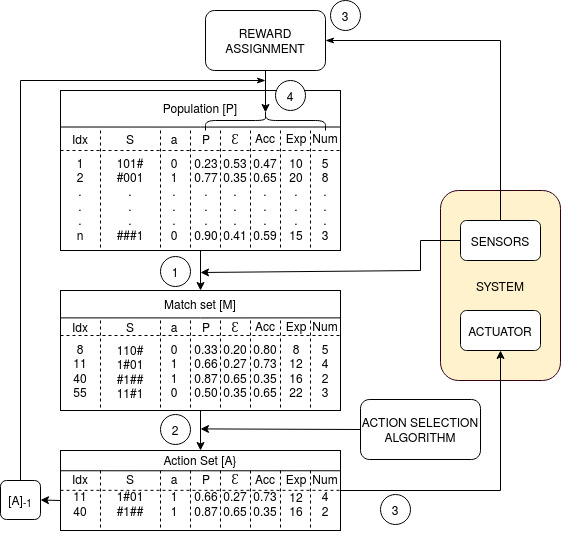
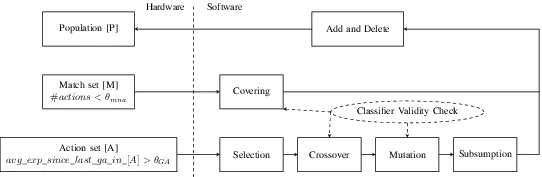
3. Classifier generation and evolution using genetic algorithms. (Article) LCTs are explainable and interpretable classifier based systems. The knowledge learnt by the LCTs is stored as a population of classifiers. An initial population of classifiers can be generated at design time using simulation tools. However, the LCTs are used in runtime to obtain changing goals and constraints. Such a static initial population leads to inefficient learning and control. The classifiers have to be updated in runtime. In this work, we explore using genetic algorithms to modify and update the classifier population in runtime.
A genetic algorithm framework for generating classifiers in runtime for LCT.
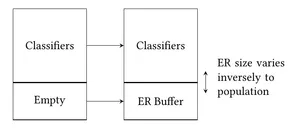
4. Experience replay for LCTs. (Article) Experience replay is a popular strategy in machine learning used to accelarate and improve the learning process. In this work, we propose to extend LCTs with experience replay. LCTs are implemented in hardware and implementing an ER buffer requires additional memory and is expensive. We observe that the entire LCT population is not always 100% occupied based on the progress in learning. We reuse the unused slots in the LCT table as an ER buffer thus increasing the performance of the LCTs while requiring no additional memory.
LCT with dyamic sized experience replay
5. Transfer learning in LCTs for faster learning to adapt to dynamically changing performance targets and constraints. LCTs are used to learn and adapt to changing goals and constraints via trial and error. The different goals and constraints depict a different reward function. A policy learned by the LCT for a particular reward function might be bad for another reward function. The knowledge in the LCT is explainable and interpretable. This gives us the opportunity to selectively transfer certain knowledge when there is a change in the reward function.
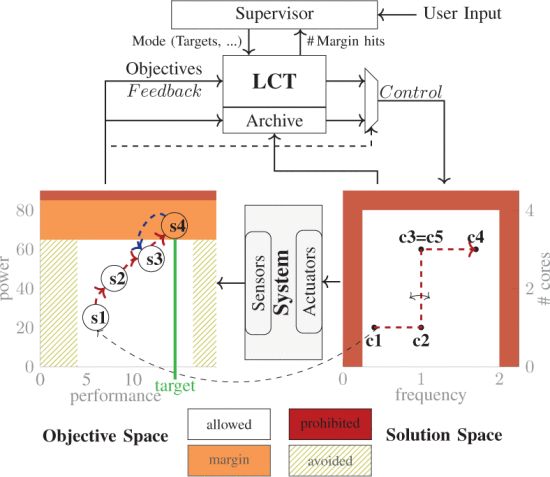
6. Archive based safety mechanism for safe runtime learning. (Article) LCTs are reinforcement learning agents which learn by trial and error to achieve an IPS target within a power budget. Violation of power budgets might lead to thermal violations which is detrimental for the chip. In this work, we propose a margin zone and a archive based safety mechanism to ensure safe runtime learning by the LCTs. The margin zone is a pre-designed zone within the power budget which the LCTs learn not to exceed. Any violation of the margin zone triggers the archive mechanism which restores the operating point of the LCTs back to the last safe point. More details available in the article.
LCTs implemented with margin zone and archive mechanism.
Anmol Prakash Surhonne, Haitham S. Fawzi, Florian Maurer, Oliver Lenke, Michael Meidinger, Thomas Wild, Andreas Herkersdorf: EPIC-Q : Equivalent-Policy Invariant Comparison enhanced transfer Q-learning for run-time SoC performance-power optimization. International Conference on Embedded Computer Systems: Architectures, Modeling and Simulation 2024, 2024 more…BibTeX
Anmol Surhonne, Manuel Wensauer, Florian Maurer, Thomas Wild, Andreas Herkersdorf: XCS with dynamic sized experience replay for memory constrained applications. Genetic and Evolutionary Computing Conference (GECCO), 2024 more…BibTeX
Full text (
DOI
)
2023
Anmol Prakash Surhonne, Florian Maurer, Thomas Wild, Andreas Herkersdorf: LCT-TL: Learning Classifier Table (LCT) with Transfer Learning for run-time SoC performance-power optimization. 16th IEEE International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC 2023), 2023 more…BibTeX
Anmol Prakash Surhonne, Florian Maurer, Thomas Wild, Andreas Herkersdorf: LCT-DER: Learning Classifier Table with Dynamic-sized Experience Replay for run-time SoC performance-power optimization. The Genetic and Evolutionary Computation Conference (GECCO), 2023 more…BibTeX
Full text (
DOI
)
Klajd Zyla, Florian Maurer, Thomas Wild, Andreas Herkersdorf: CoLeCTs: Cooperative Learning Classifier Tables for Resource Management in MPSoCs. 36th International Conference on Architecture of Computing Systems, ARCS 2023, 2023 more…BibTeX
Full text (
DOI
)
Maurer, Florian; Thoma, Moritz; Surhonne, Anmol Prakash; Donyanavard, Bryan; Herkersdorf, Andreas: Machine Learning in Run-Time Control of Multicore Processor Systems. it - Information Technology 0 (0), 2023 more…BibTeX
Full text (
DOI
)
Nora Sperling, Alex Bendrick, Dominik Stöhrmann, Rolf Ernst, Bryan Donyanavard, Florian Maurer, Oliver Lenke, Anmol Surhonne, Andreas Herkersdorf, Walaa Amer, Caio Batista de Melo, Ping-Xiang Chen, Quang Anh Hoang, Rachid Karami, Biswadip Maity, Paul Nikolian, Mariam Rakka, Dongjoo Seo, Saehanseul Yi, Minjun Seo, Nikil Dutt, Fadi Kurdahi: Information Processing Factory 2.0 - Self-awareness for Autonomous Collaborative Systems. DATE 2023, 2023 more…BibTeX
Full text (
DOI
)
2022
Anmol Prakash Surhonne, Nguyen Anh Vu Doan, Florian Maurer, Thomas Wild, and Andreas Herkersdorf: GAE-LCT: A Run-Time GA-Based Classifier Evolution Method for Hardware LCT Controlled SoC Performance-Power Optimization. Architecture of Computing Systems, 2022 more…BibTeX
Full text (
DOI
)
2021
Biswadip Maity, Bryan Donyanavard, Anmol Prakash Surhonne, Amir Rahmani, Andreas Herkersdorf, Nikil Dutt: SEAMS: Self-Optimizing Runtime Manager for Approximate Memory Hierarchies. ACM Transactions on Embedded Computing Systems (TECS), 2021 more…BibTeX
Full text (
DOI
)
2020
Eberle Andrey Rambo; Bryan Donyanavard; Minjun Seo; Florian Maurer; Thawra Mohammad Kadeed; Caio Batista De Melo; Biswadip Maity; Anmol Surhonne; Andreas Herkersdorf; Fadi Kurdahi; Nikil D. Dutt; Rolf Ernst: The Self-Aware Information Processing Factory Paradigm for Mixed-Critical Multiprocessing. IEEE Transactions on Emerging Topics in Computing, 2020, 1-1 more…BibTeX
Full text (
DOI
)
Florian Maurer, Bryan Donyanavard, Amir M. Rahmani, Nikil Dutt, Andreas Herkersdorf: Emergent Control of MPSoC Operation by a Hierarchical Supervisor / Reinforcement Learning Approach. DATE 2020, 2020 more…BibTeX
Full text (
DOI
)
2019
Donyanavard, Bryan; Sadighi, Armin; Maurer, Florian; Mück, Tiago; Rahmani, Amir M.; Herkersdorf, Andreas; Dutt, Nikil: SOSA: Self-Optimizing Learning with Self-Adaptive Control for Hierarchical System-on-Chip Management. Proceedings of the 52Nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO '52), ACM, 2019 more…BibTeX
Full text (
DOI
)
Rambo, Eberle A.; Kadeed, Thawra; Ernst, Rolf; Seo, Minjun; Kurdahi, Fadi; Donyanavard, Bryan; de Melo, Caio Batista; Maity, Biswadip; Moazzemi, Kasra; Stewart, Kenneth; Yi, Saehanseul; Rahmani, Amir M.; Dutt, Nikil; Maurer, Florian; Doan, Nguyen Anh Vu; Surhonne, Anmol; Wild, Thomas; Herkersdorf, Andreas: The Information Processing Factory: A Paradigm for Life Cycle Management of Dependable Systems. ESweek, 2019 more…BibTeX
Full text (
DOI
)
2018
Mischa Möstl, Johannes Schlatow, Rolf Ernst, Nikil Dutt, Ahmed Nassar, Amir Rahmani, Fadi J. Kurdahi, Thomas Wild, Armin Sadighi, Andreas Herkersdorf: Platform-Centric Self-Awareness as a Key Enabler for Controlling Changes in CPS. IEEE, 2018 Proceedings of the IEEEmore…BibTeX
Armin Sadighi, Bryan Donyanavard, Thawra Kadeed, Kasra Moazzemi, Tiago Mück, Ahmed Nassar, Amir M. Rahmani, Thomas Wild, Nikil Dutt, Rolf Ernst, Andreas Herkersdorf, Fadi Kurdahi: Design methodologies for enabling self-awareness in autonomous systems. 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), IEEE, 2018 more…BibTeX