Research Agenda at the ATARI Lab
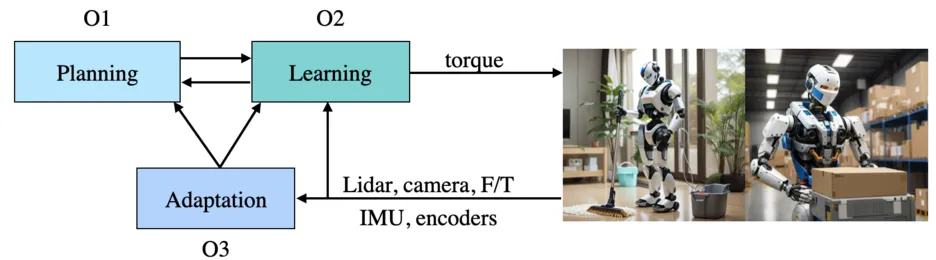
The Applied and Theoretical Aspects of Robot Intelligence (ATARI) Lab envisions a future where humanoid robots autonomously perform complex tasks in dynamic and unstructured environments. Consider a scenario where a robot tidies a cluttered house each day, encountering different configurations and challenges. This vision requires the robot to:
- Plan sequences of actions (O1) in novel situations.
- Leverage learning to offload computation and continually improve behaviours (O2) while accounting for safety.
- Adapt behaviour while interacting with diverse objects and surfaces (O3) reliably and effectively.
To date, no existing framework offers the generality, adaptability, and robustness required for such tasks. At ATARI, we develop foundational principles and frameworks to endow robots with these capabilities. Drawing on model-based control, trajectory optimisation, task and motion planning, imitation learning, reinforcement learning, and generative modelling, we aim to harness the strengths of both model-based and data-driven paradigms to advance the frontiers of robotics.
To find videos of our research, check out our YouTube Channel. To follow our latest research developments, follow us on LinkedIn.
Planning (O1)
Motion Retargeting from Humans
Humans are an unparalleled source of dexterous, contact-rich behaviour. Raw human motions are kinematically incompatible with robot morphologies and, more fundamentally, physically infeasible when naively transferred. Bridging this gap requires motion retargeting: converting human demonstrations into dynamically feasible robot trajectories that can serve as high-quality data for imitation learning or as reference motions for tracking controllers.
Our work, DynaRetarget, introduces a complete pipeline for retargeting human motions to humanoid control policies. At its core is a novel Sampling-Based Trajectory Optimisation (SBTO) framework that refines imperfect kinematic trajectories into dynamically feasible motions by incrementally advancing the optimisation horizon — enabling optimisation over the full trajectory even for long-horizon tasks where fixed-horizon methods fail. DynaRetarget successfully retargets hundreds of humanoid–object interaction demonstrations, achieves higher success rates than the state of the art, and generalises across varying object properties — mass, size, and geometry — using the same unified tracking objective. This capability opens the door to generating large-scale synthetic datasets of physically valid humanoid loco-manipulation trajectories, directly addressing the data bottleneck that limits imitation learning at scale.
Task and Motion Planning for Loco-Manipulation
Tasks such as cleaning, assembling objects, or rearranging furniture involve multiple interdependent subtasks, each requiring precise execution and adaptability. ATARI's research focuses on hierarchical task decomposition, encoding this structure in a holistic planning and control framework. Our work on Task and Motion Planning (TAMP) for humanoid loco-manipulation unifies locomotion and manipulation planning through a shared contact-mode representation. A tree-search algorithm over symbolic contact states guides a contact-explicit trajectory optimisation (TO) solver that optimises whole-body motion — covering both robot and object dynamics — over long action sequences. Results on a humanoid platform demonstrate that this approach generates a broad range of physically consistent loco-manipulation behaviours that require complex, long-horizon reasoning.
Contact as a Unifying Abstraction
The power of abstraction lies in its ability to represent complex systems concisely. In vision, convolutional filters revolutionised learning by embedding spatial hierarchies; in language, transformers demonstrated the utility of attention mechanisms. In robotics, we hypothesise that physical contacts with the environment are one of the key abstractions for planning and control of loco-manipulation. By representing symbolic actions as contact-mode changes — grounding high-level decisions in low-level physics — we can bridge task, contact, and motion planning in a unified framework. Our recent works on contact-conditioned locomotion policy learning through imitation learning and multi-task robot policies through reinforcement learning for quadruped locomotion and humanoid manipulation demonstrate that contact-explicit formulations improve generalisation to unseen scenarios and can be deployed zero-shot to real hardware seamlessly.
Diffusion Models as Contact Planners
Standard model-based controllers rely on fixed contact sequences and struggle in highly constrained or agile settings. We explored using diffusion models to learn distributions over contact plans, combining NMPC for motion generation with Monte Carlo Tree Search (MCTS) for plan search and a diffusion prior to guide that search. Applied to agile locomotion on stepping stones, this hybrid approach achieves robust performance that neither model-based nor learning-based methods achieve alone. We further developed learning feasible transitions for efficient contact planning, combining dynamic feasibility classifiers with low-level control compensation for real hardware deployment. We are extending this paradigm to loco-manipulation, using Latent Diffusion Models (LDMs) to generate physically consistent long-horizon plans for humanoid robots operating in complex environments.
Foundation Models for Planning
The scale and semantic richness of modern generative models — from Latent Diffusion Models trained on video and motion data to Vision-Language Models trained on internet-scale text and images — open a powerful new avenue for robot planning: using these models as world-knowledgeable priors over physically plausible action sequences, rather than relying solely on hand-crafted planners or task-specific simulation environments.
Our work on Physically Consistent Humanoid Loco-Manipulation using Latent Diffusion Models demonstrates that LDMs trained on human-object interaction data encode rich priors over plausible contact configurations. By extracting contact locations and whole-body poses from LDM-generated scenes and using them to warm-start a trajectory optimisation solver, we obtain physically feasible long-horizon plans for humanoid loco-manipulation — without requiring task-specific demonstrations or hand-designed cost functions. The result is a planner that generalises to novel objects and scenes by leveraging the broad distribution captured by the generative model.
Vision-Language-Action (VLA) models extend to open-vocabulary task specification. Pre-trained VLMs encode commonsense knowledge about object affordances, spatial relationships, and action semantics that can be queried to decompose high-level language instructions into contact-level subgoals. At ATARI, we investigate how to ground VLA outputs in physically consistent contact plans — bridging the gap between semantic intent and the low-level trajectory optimisation that actually executes the plan on the robot.
Optimal Control, Deep RL, and Beyond
Optimal control leverages simulation gradients to plan efficiently; deep reinforcement learning samples in simulation to estimate gradients, excelling in robustness. Neither fully satisfies the needs of general-purpose robots. At ATARI, we investigate hybrid approaches that leverage the strengths of both. A key bottleneck shared by many existing methods — MPPI, CEM, CMA-ES — is that they are local in nature and thus susceptible to poor local optima. Our work on Consensus-Based Optimisation (CBO): Towards Global Optimality in Robotics introduces CBO to robotics as a gradient-free, sampling-based optimiser in which a population of candidate solutions collaboratively drift toward promising regions of the search space, and is guaranteed to converge to a global optimum under mild assumptions.
Planning in Novel Situations
Effective planning in unstructured environments involves addressing vast, high-dimensional state spaces and generating feasible action sequences in real time. ATARI Lab investigates methods across learning and model-based approaches to efficiently plan in large state spaces and to create algorithms that scale across diverse scenarios.
Learning (O2)
Reinforcement Learning on Humanoids for Loco-Manipulation
Training general-purpose policies for humanoid robots is challenging due to the combinatorial diversity of tasks and the difficulty of defining shared goal representations. We address this by grounding task specification in contact goals — desired contact positions, timings, and active end-effectors — which provide a unified language across locomotion and manipulation. Our work on Learning to Act Through Contact trains goal-conditioned RL policies that realise arbitrary contact plans, demonstrating a single policy capable of performing multiple bipedal and quadrupedal gaits as well as bimanual manipulation tasks on humanoid platforms. This contact-explicit RL framework is a foundation for scalable, multi-task loco-manipulation. Earlier, contact-conditioned multi-gait policy learning validated that contact-conditioned policies generalise significantly better than common goal representations when tested out-of-distribution.
Diffusion Policies for Dexterous Manipulation
Diffusion models offer powerful priors for modelling multi-modal action distributions, making them well-suited for contact-rich manipulation. Our work on Physically Consistent Humanoid Loco-Manipulation using Latent Diffusion Models demonstrates that extracting contact locations and robot configurations from LDM-generated human-object interaction scenes, and using them to initialise whole-body trajectory optimisation, yields physically consistent trajectories for long-horizon humanoid loco-manipulation. We are further investigating how to scale such policies to closed-loop visuomotor control.
Vision-Language-Action (VLA) Models for Embodied Tasks
The emergence of large-scale foundation models has opened new avenues for grounding natural language and visual understanding directly in robotic action. At ATARI, we are exploring Vision-Language-Action (VLA) models as a means to enable humanoid robots to understand rich task descriptions, reason about novel object configurations, and execute multi-step manipulation policies — all within a unified architecture. A key challenge is bridging the semantic knowledge of pre-trained VLMs with the physical constraints of contact-rich manipulation. We investigate how to effectively fine-tune and ground VLAs using robot-specific inductive biases (e.g. contact representations) and hybrid architectures that combine language-conditioned high-level reasoning with low-level diffusion-based action generation.
Training Generalisable Policies
Robot policies must generalise across diverse embodiments and tasks. In imitation learning, a major bottleneck is the lack of large-scale, high-quality data akin to internet-scale datasets for language models. For reinforcement learning, challenges include defining generic goal representations and reward structures that accommodate diverse contact-rich tasks. Our survey of learning-based legged locomotion synthesises the state of the art and outlines key open problems, including sim-to-real transfer, compliant contact modelling, and safe online adaptation. At ATARI, we develop methods to learn from limited data and to transfer knowledge across embodiments and task families.
Learning Safely in the Real World
Learning directly in the real world remains a formidable challenge due to the high sample complexity of state-of-the-art algorithms, coupled with safety considerations. Our work on safe learning of locomotion skills from MPC uses iterative imitation learning with a safe data aggregation strategy (SafeDAGGER) to dramatically reduce the number of failures during training while producing policies that are more robust to external disturbances. We continue to explore strategies for safe and efficient real-world learning across a broader range of contact-rich tasks.
Adaptation (O3)
Handling Uncertainty in Real-World Environments
Simulators fail to capture the full spectrum of uncertainties robots face, such as material properties, contact uncertainties, etc. At ATARI, we focus on enabling robots to detect out-of-distribution scenarios and respond reliably through robust policy adaptation and uncertainty-aware decision-making. Our trajectory optimisation under contact timing uncertainties and the SURE framework directly address this challenge at the planning level, while multi-contact stochastic predictive control handles contact location uncertainty at the MPC level.
Developing Adaptive and Robust Policies
Designing robust and adaptive policies for hybrid dynamical systems is notoriously difficult. Current reinforcement learning techniques rely heavily on domain randomisation to handle variability, but this approach can lead to unnecessary conservativeness. Instead, we investigate adaptive policies that adjust dynamically to new environments. The goal-conditioned from DynaRetarget (trajectories) and Learning to Act Through Contact (contact) provide a natural handle for adaptation: by changing the motion references or contact goals, the same underlying policy can be redirected to a wide range of tasks and environments without retraining. We are further investigating several directions to equip robots with the ability to learn and adapt in real time.
Foundation Models for Open-World Adaptation
A key advantage of VLA models is their ability to leverage the broad world knowledge encoded in pre-trained vision-language backbones. At ATARI, we investigate how VLAs can enable open-world generalisation — recognising novel objects, interpreting ambiguous instructions, and generating appropriate contact strategies in previously unseen environments. We study how to combine the semantic flexibility of VLMs with the physical grounding provided by our model-based contact representations.
Our Vision
ATARI Lab is committed to advancing robotics research to create robots capable of autonomous loco-manipulation, adaptive planning, and seamless learning in unstructured environments. By addressing the fundamental challenges of planning, learning, and adaptation — and by tightly integrating model-based rigour with the representational power of modern generative and foundation models — we aim to develop the foundational frameworks for a future where humanoid robots are reliable collaborators in dynamic, human-centric settings.